この記事はmikan Advent Calendar 2023の5日目の記事です。
この記事では、mikanが提供している教材学習システムの裏側について触れていますので、ご興味があれば読んでいただけますと嬉しいです。
なお、mikan Advent Calendar 2023の他の記事は下記のリンクからご覧ください。
adventar.org
mikanQTについて
mikanでは、様々な学習教材が掲載されており、例えばTOEIC ®対策の教材や、英検®対策の教材などたくさんの種類があります。
TOEIC ®はPart1〜Part7まで、英検®は短文の語句空所補充や長文の内容一致選択、会話の内容一致選択など、多くの問題形式が存在し、試験対策用の学習教材は特に、それらの問題形式に基づいてコンテンツが用意されていることがほとんどです。
mikanでは問題形式のことをQuestionTypeと呼んでおり、mikanの学習体験をベースにQuestionTypeを再設計したものがmikanQTです。
なぜQuestionTypeを再設計するのか
Contents QuestionTypeのツラミ
説明の都合上、TOEIC ®のPart1のようなQuestionTypeを、便宜的にContents QuestionTypeとします。
これまではContents QuestionTypeをそのままの形式で利用してAPI からデータを返していました。
具体例がないと理解しづらいと思いますので、実際の入稿フローの一部を紹介します。
入稿
まず、書籍のデータをAPI で扱えるようにするため(=つまりDBに格納するため)に、入稿データを作ります。
入稿シートがあるので、Contents QuestionTypeが持つフィールド(以下、Attribute)に割り当てていきます。
各カラムの4行目はAttributeのキーに対応しており、これらのキー名とともに、値がDBに保存されます。
API はDBのデータを取り出し、必要に応じてデータを加工してレスポンスします。
for _, attr := range attrs {
var parsedAttr domain.QuestionAttribute
typeID := domain.QuestionTypeID(types[attr.QuestionID])
switch typeID {
case domain.QUESTION_TYPE_TOEIC_PART_1:
a, err := i.parseTOEICPart1Attr(attr)
if err != nil {
return nil , err
}
}
加工処理の中では、音声や画像などのアセットのURLを作る処理や、部分的なHTMLを作るためのテンプレートパース処理など、Contents QuestionTypeに応じた細かなプログラムが書かれています。
最終的に、QuestionAttributeとしてまとめてデータを返します。
type QuestionAttribute struct {
QuestionID string `json:"question_id"`
AudioTextEN string `json:"audio_text_en,omitempty"`
AudioTextJA string `json:"audio_text_ja,omitempty"`
AudioSentenceEN string `json:"audio_sentence_en,omitempty"`
AudioSentenceJA string `json:"audio_sentence_ja,omitempty"`
AudioContextSentenceEN string `json:"audio_context_sentence_en,omitempty"`
AudioContextSentenceJA string `json:"audio_context_sentence_ja,omitempty"`
AudioContextSentenceHTMLEN string `json:"audio_context_sentence_html_en,omitempty"`
AudioContextSentenceHTMLJA string `json:"audio_context_sentence_html_ja,omitempty"`
AudioURL string `json:"audio_url,omitempty"`
ResultAudioURL string `json:"result_audio_url,omitempty"`
CombinedAudioURL string `json:"combined_audio_url,omitempty"`
AudioFilename string `json:"audio_filename,omitempty"`
ResultAudioFilename string `json:"result_audio_filename,omitempty"`
CombinedAudioFilename string `json:"combined_audio_filename,omitempty"`
BlankedSentenceEN string `json:"blanked_sentence_en,omitempty"`
ContextSentenceEN string `json:"context_sentence_en,omitempty"`
ContextSentenceJA string `json:"context_sentence_ja,omitempty"`
Description string `json:"description,omitempty"`
DescriptionEN string `json:"description_en,omitempty"`
DescriptionJA string `json:"description_ja,omitempty"`
Explanation string `json:"explanation,omitempty"`
SentenceEN string `json:"sentence_en,omitempty"`
SentenceJA string `json:"sentence_ja,omitempty"`
RecommendedAnswerSecondsCaption string `json:"recommended_answer_seconds_caption,omitempty"`
ContextSentenceHTMLEN string `json:"context_sentence_html_en,omitempty"`
ContextSentenceHTMLJA string `json:"context_sentence_html_ja,omitempty"`
ExplanationHTML string `json:"explanation_html"`
SentenceHTMLEN string `json:"sentence_html_en,omitempty"`
SentenceHTMLJA string `json:"sentence_html_ja,omitempty"`
SentenceHTML string `json:"sentence_html,omitempty"`
SentenceCommentaryHTML string `json:"sentence_commentary_html,omitempty"`
SentenceCommentaryEN string `json:"sentence_commentary_en,omitempty"`
SentenceCommentaryJA string `json:"sentence_commentary_ja,omitempty"`
ResultSentenceHTML string `json:"result_sentence_html,omitempty"`
ResultSentenceHTMLEN string `json:"result_sentence_html_en,omitempty"`
ResultSentenceHTMLJA string `json:"result_sentence_html_ja,omitempty"`
VocabularyHTML string `json:"vocabulary_html"`
AnswerChoice string `json:"answer_choice,omitempty"`
AnswerChoicesCommaSeparatedTextEN string `json:"answer_choices_comma_separated_text_en,omitempty"`
AnswerChoicesCommaSeparatedTextJA string `json:"answer_choices_comma_separated_text_ja,omitempty"`
AnswerChoicesEN []string `json:"answer_choices_en,omitempty"`
AnswerChoicesJA []string `json:"answer_choices_ja,omitempty"`
AnswerListSentenceHTML string `json:"answer_list_sentence_html,omitempty"`
AnswerRearrangedChoicesCommaSeparatedTextEN string `json:"answer_rearranged_choices_comma_separated_text_en,omitempty"`
AnswerRearrangedChoicesCommaSeparatedTextJA string `json:"answer_rearranged_choices_comma_separated_text_ja,omitempty"`
AnswerRearrangedChoicesEN []string `json:"answer_rearranged_choices_en,omitempty"`
AnswerRearrangedChoicesJA []string `json:"answer_rearranged_choices_ja,omitempty"`
AnswerSentencePartialHTML string `json:"answer_sentence_partial_html,omitempty"`
AnswerSentencePartialHTMLEN string `json:"answer_sentence_partial_html_en,omitempty"`
AnswerSentencePartialHTMLJA string `json:"answer_sentence_partial_html_ja,omitempty"`
RecommendedAnswerSeconds uint64 `json:"recommended_answer_seconds,omitempty"`
*QuestionMultiattribute
}
クライアント
クライアントは、必要なデータをレスポンスから取り出してViewに描画したり、回答のロジックを作ったりしています。
public struct Part1Question : ExamQuestionProtocol , Codable, Equatable {
public let id : String
public let orderNumber : Int
public let displayId : String
public let audioUrl : String
public let imageEntities : [ String ]
public var imageUrl : String {
return imageEntities.first!
}
public let explanationHtml : String
public let choices : [ Exam.Choice ]
public let title = ""
public let recommendedAnswerSeconds : Int
public let combinedAudioUrl : URL
}
お気づきの方もいらっしゃると思いますが、API が持つモデルQuestionAttributeの各フィールドが、omitemptyとなっています。
これは、AttributeがEAV(Entity Attribute Value )パターンでテーブル設計されていることが理由です。
おそらく、教材によって同じ問題形式でも異なる表現方法があり、模索しながら抽象化していく経緯があって、スキーマ を柔軟に変更できるEAVを採用したのだと推察しています。
実際に、このようなデータがテーブルに格納されています。
上記の表を取得するためには下記のSQL を発行する必要があります。
SELECT
q.id,
qat. `name`,
qa. `value`
FROM
questions q
JOIN question_attributes qa ON qa.question_id = q.id
JOIN question_attribute_types qat ON qa.question_attribute_type_id = qat.id
JOIN question_units qu ON q.question_unit_id = qu.id
JOIN chapters c ON qu.chapter_id = c.id
JOIN books b ON c.book_id = b.id
WHERE
b.id = " 01GHAZTZTAREG4SDYK9BJ7QJ20 " ;
EAVを利用することで、以下のようなデメリットが発生していました。
特定のAttributeへのNOT NULLやデータサイズなどの制約を付与できない
Contents QuestionTypeに必須なキーの入稿漏れに気づけない
不必要に大きいデータを入稿できてしまう
データを取得するために多くのJOINが必要で、SQL が複雑になる
入稿ミス時の状況確認や、API で不具合が発生したときの調査が大変
不整合の検知が難しい
Contents QuestionTypeによっては、必要ないAttributeもまとめてEAVとして管理している関係でNullableな要素が多く、それをQuestionAttributeとして一つのモデルで表現したことで、クライアントのデコードエラーを引き起こしたり、入稿ミスや不具合発生時の調査を遅らせたりしていました。
さらに、提携教材が増えていくとContents QuestionTypeも増えていきます。
Contents QuestionTypeに必要なAttributeはどれで、オプショナルなAttributeはどれなのか、管理がどんどん難しくなっていきます。
各Contents QuestionTypeの型定義がないのも要因の一つでした。
また、例えば「ほとんどPart1と似た形だが微妙に異なるフィールドが必要」な教材を掲載したくなったときに、Contents QuestionTypeの再設計及び実装が必要になります。
解決策としてのmikanQT
ここまでで、Contents QuestionTypeをAPI でそのまま扱ってしまうと、下記の問題があることを説明しました。
Contents QuestionTypeごとに必要なAttributeとオプショナルなAttributeの区別が難しかった
Attributeの微妙な違いで、新たにContents QuestionTypeを増やさなければならないケースがあった
EAVはともかく、教材データをもとにして入稿データを作成するところまでは良いのですが、それをそのままの形でAPI が利用していたことが問題だったため、mikanの学習体験を起点にしたQuestionTypeを作成することにしました。その理由を述べるには、既存のContents QuestionTypeの特徴を説明する必要があります。
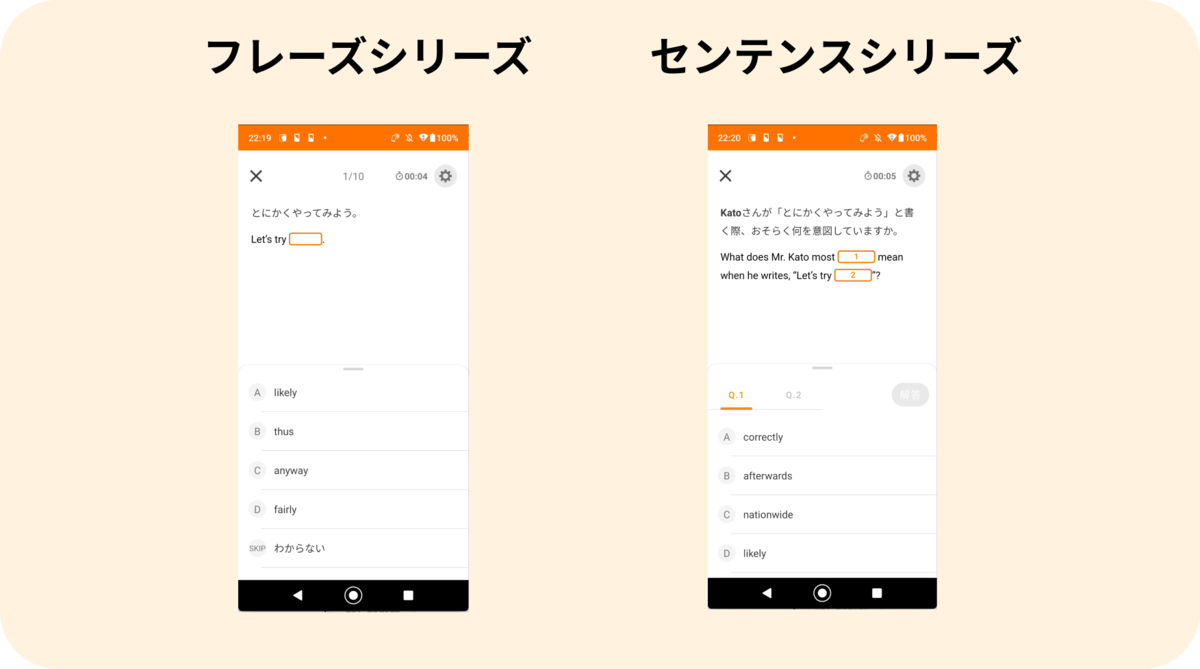
TOEIC Part 5や短文の語句空所補充を例に挙げます。
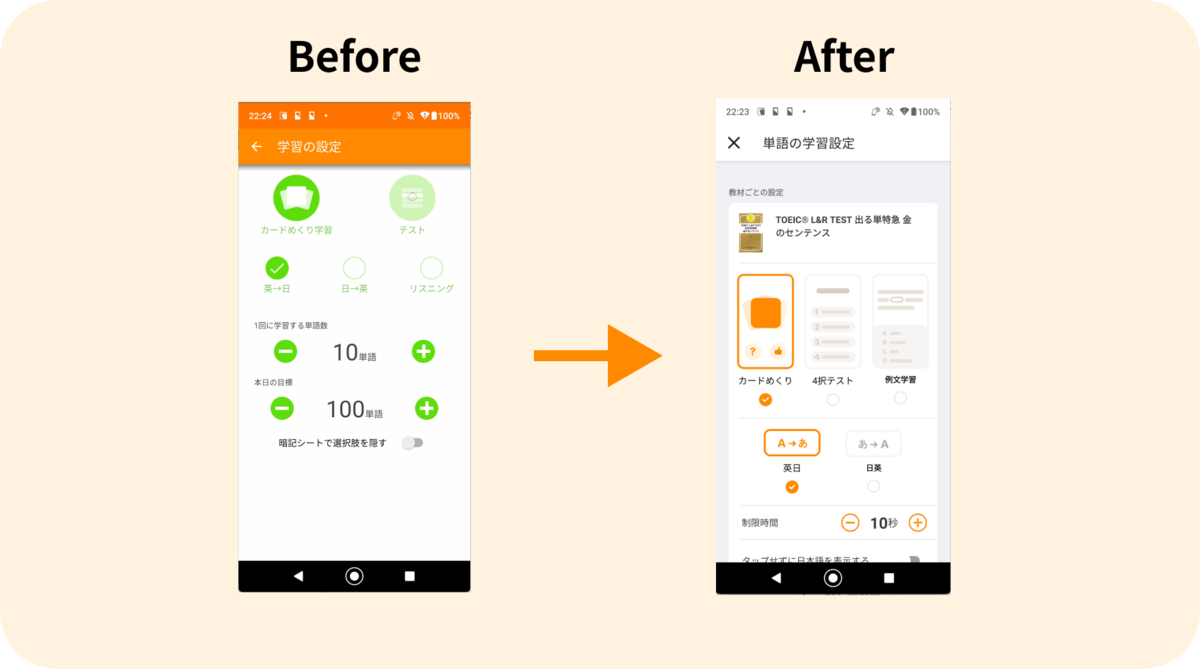
mikanの学習画面
これまでのContents QuestionTypeの設計の場合、問題文や解説を構成する要素が教材や試験の問題形式によって異なっていたため、別のContents QuestionTypeとして設計されていました。
これらをmikanでの学習体験から考えると、問題文があり、4択で解答ができて、解説を見れるという体験は共通になっています。
つまり、それらの体験を満たせる型を定義すれば、上述した問題をひとまず解消することができます。
続いて、mikanQTの具体例を見ていきます。
まずはGo言語の構造体の定義の例を以下に示します。
type StringComponent struct {
Text string `json:"text"`
Type StringComponentType `json:"type"`
}
const (
StringComponentTypePlain StringComponentType = "plain"
StringComponentTypePartialHTML StringComponentType = "partial_html"
StringComponentTypeHTML StringComponentType = "html"
StringComponentTypeImageURL StringComponentType = "image_url"
)
type QuestionComponentReadingUnitChoices struct {
Result *QuestionComponentReadingUnitChoicesResult `json:"result"`
Sentence *StringComponent `json:"sentence"`
Choices []*QuestionChoice `json:"choices"`
}
type QuestionComponentReadingUnitChoicesResult struct {
Headline *StringComponent `json:"headline"`
Sentence *StringComponent `json:"sentence"`
}
似たような型が並んでいて少々見づらいのですが、QuestionAttributeに比べると、問題文、選択肢、解説画面など、学習に必要な要素をシンプルに表現できているかと思います。
mikanではクライアントとの通信の一部にGraphQLを利用しているため、GraphQLスキーマ も定義しています。
type Question implements Node {
id : ID !
displayId : String !
orderNumber : Int !
components : QuestionComponents !
}
union QuestionComponents =
QuestionComponentReadingUnitChoices
| QuestionComponentReadingChoices
| QuestionComponentListeningUnitChoices
| QuestionComponentListeningChoices
type QuestionComponentReadingUnitChoices {
result : QuestionComponentReadingUnitChoicesResult !
sentence : StringComponent
choices : [ QuestionChoice ! ] !
}
type QuestionComponentReadingUnitChoicesResult {
headline : StringComponent !
sentence : StringComponent !
}
これにより、クライアントとしてもcomponentsの__typenameを見ることで適切なUIに切り替えることができます。
Contents QuestionTypeは学習体験ベースでmikanQTに集約され、オプショナルの問題もスキーマ レベルで解消されています。
進め方
実際にmikanQTを導入していくために、いくつかのステップが必要になります。
既存のContents QuestionTypeの洗い出し
クライアントの画面と、利用しているAttributeの一覧をマッピング する
mikanQTのGraphQLスキーマ を定義する
Contents QuestionTypeごとにマイグレーション スクリプト を書く
マイグレーション スクリプト を実行するリゾル バを実装する
1. 既存のContents QuestionTypeの洗い出し
まずは、mikanで取り扱っているContents QuestionTypeを洗い出す必要があります。
これはContents QuestionTypeを管理しているテーブルからデータを取得するだけで完了となります。
2. クライアントの画面と、利用しているAttributeの一覧をマッピング する
ここが一番辛い作業です。
API で定義したAttribute名とクライアントで利用しているモデルのフィールド名に差分があったり、API が返したデータをクライアントでさらに加工している部分があったりと、紐解くのが大変でした。
型定義書もなく、API はほぼオプショナルで返してしまっているので、クライアントチームに多大なご協力をいただきContents QuestionTypeごとに利用しているAttributeを洗い出していただきました。
Attributeの洗い出し作業の様子
各Contents QuestionTypeごとにAttributeを洗い出したら、それぞれ似たものを集約できないかを考えてまとめていきます。
現時点では、4種類に分類することができました。
スプレッドシート でAttributeのチェック作業
3. mikanQTのGraphQLスキーマ を定義する
必要なmikanQTと、それに付随するAttributeが判明したので、GraphQLスキーマ 、Goの構造体を定義していきます。
実際のコードの一部は上述したたため、割愛します。
4. Contents QuestionTypeごとにマイグレーション スクリプト を書く
生のAttributeからAPI レスポンス用にデータを加工する処理がContents QuestionTypeごとに書かれているため、API の見通しが悪くなっていました。
この問題に対し、あらかじめデータを加工した状態でデータを持っておけば、API の仕事が減って見通しも良くなると考え、API が行っていた処理をマイグレーション スクリプト として実装し、加工済みデータを保存しておくことにしました。
EAVのままでは多段のJOINが必要という問題もあったため、一旦はMySQL のテーブルにJSON 型で保存することでJOINなしでデータを引けるようにしました。
JSON 型を利用しても、データ型や必須属性を制約としてつけられないといったEAVのデメリットはそのままですが、マイグレーション スクリプト 上でも上述した構造体を参照することで型を担保しています。
また、JSON 型を利用した際のパフォーマンスの懸念がありますが、SQL でJSON 関数を呼び出すこともなく、そのままUnmarshalされるのでDBのCPU負荷としては今のところ問題ありません。
※ただし、巨大なJSON を持つレコードがあるとクエリ応答がかなり遅くなるケースもあることが分かっているため、こちらはまた対処したいと思っています。
QuestionAttributeを返すAPI のレスポンスと、マイグレーション スクリプト によって作成されたJSON が一致することを確認しながら作業を進めました。
4で作成したスクリプト を、教材ごとに実行していきます。
いきなりすべての教材に対して実行せずに、部分的に実行していくことでリスクを減らします。
マイグレーション と言っても、既存のデータをもとに加工済みデータを作成し、新たなテーブルに保存しているだけなので、既存データへの変更はありません。
6. リゾル バを実装する
mikanQTのデータはJSON 型で表現されているため、単純にDBからSELECTしたものをUnmarshalしていきます。
Unmarshal後は、Validメソッドを呼んでバリデーションをおこないます。
(バリデーションはUnmarshallerとして内部でコールしても良かったかもしれません。)
type QuestionComponent interface {
IsQuestionComponent()
Valid() error
}
func parseQuestionComponents[T QuestionComponent](raw json.RawMessage) (*T, error ) {
var components T
err := json.Unmarshal(raw, &components)
if err != nil {
return nil , err
}
if err = components.Valid(); err != nil {
return nil , err
}
return &components, nil
}
ジェネリクス を利用しているため型を渡す必要があるのですが、型は作業手順2で作成したContents QuestionTypeとmikanQTのマッピング を利用して判定します。
func ParseMikanQuestionTypeFromQuestionTypeID(questionTypeID string ) (QuestionTypeID, error ) {
switch questionTypeID {
case QUESTION_TYPE_TOEIC_PART_1.String(), QUESTION_TYPE_TOEIC_PART_2.String(), QUESTION_TYPE_LISTENING_CHOICES.String():
return QUESTION_TYPE_LISTENING_CHOICES, nil
case QUESTION_TYPE_TOEIC_PART_3.String(), QUESTION_TYPE_TOEIC_PART_4.String(), QUESTION_TYPE_LISTENING_UNIT_CHOICES.String():
return QUESTION_TYPE_LISTENING_UNIT_CHOICES, nil
case QUESTION_TYPE_TOEIC_PART_5.String(), QUESTION_TYPE_READING_CHOICES.String():
return QUESTION_TYPE_READING_CHOICES, nil
case QUESTION_TYPE_TOEIC_PART_6.String(), QUESTION_TYPE_TOEIC_PART_7.String(), QUESTION_TYPE_READING_UNIT_CHOICES.String():
return QUESTION_TYPE_READING_UNIT_CHOICES, nil
}
return "" , fmt.Errorf("ParseMikanQuestionTypeFromQuestionTypeID failed: arg = %q" , questionTypeID)
}
func (q *Question) parseComponents(questionTypeID string ) error {
mikanQT, err := ParseMikanQuestionTypeFromQuestionTypeID(questionTypeID)
if err != nil {
return err
}
switch mikanQT {
case QUESTION_TYPE_READING_UNIT_CHOICES:
c, err := parseQuestionComponents[QuestionComponentReadingUnitChoices](q.RawComponents)
if err != nil {
return err
}
q.Components = c
case QUESTION_TYPE_READING_CHOICES:
c, err := parseQuestionComponents[QuestionComponentReadingChoices](q.RawComponents)
if err != nil {
return err
}
q.Components = c
case QUESTION_TYPE_LISTENING_UNIT_CHOICES:
c, err := parseQuestionComponents[QuestionComponentListeningUnitChoices](q.RawComponents)
if err != nil {
return err
}
q.Components = c
case QUESTION_TYPE_LISTENING_CHOICES:
c, err := parseQuestionComponents[QuestionComponentListeningChoices](q.RawComponents)
if err != nil {
return err
}
q.Components = c
}
return nil
}
これでJSON データをmikanQT構造体へ変換できました。
なお、JSON 型で必須属性などを指定できない部分はこのようにアプリケーションで担保しています。
func (t QuestionComponentReadingUnitChoices) IsQuestionComponent() {}
func (t QuestionComponentReadingUnitChoices) Valid() error {
if t.Result == nil {
return errors.New("result is empty" )
}
if t.Result.Sentence == nil {
if t.Result.Explanation == nil {
return errors.New("result explanation is empty" )
}
if t.Result.Explanation.Text == "" {
return errors.New("result explanation text is empty" )
}
if err := t.Result.Explanation.Type.Valid(); err != nil {
return err
}
if t.Result.SentenceEN == nil {
return errors.New("result sentence_en is empty" )
}
if t.Result.SentenceEN.Text == "" {
return errors.New("result sentence_en text is empty" )
}
if err := t.Result.SentenceEN.Type.Valid(); err != nil {
return err
}
if t.Result.SentenceJA == nil {
return errors.New("result sentence_ja is empty" )
}
if t.Result.SentenceJA.Text == "" {
return errors.New("result sentence_ja text is empty" )
}
if err := t.Result.SentenceJA.Type.Valid(); err != nil {
return err
}
} else {
if t.Result.Sentence.Text == "" {
return errors.New("result sentence text is empty" )
}
if err := t.Result.Sentence.Type.Valid(); err != nil {
return err
}
if t.Result.Headline == nil {
return errors.New("result headline is empty" )
}
if t.Result.Headline.Text == "" {
return errors.New("result headline text is empty" )
}
if err := t.Result.Headline.Type.Valid(); err != nil {
return err
}
if len (t.Choices) <= 0 {
return errors.New("choices must be greater than 0" )
}
}
return nil
}
既存データとの並行運用のため、苦し紛れで条件分岐している泥臭い部分も残っています。
現状と今後の話
ここまでの作業をバックエンドチームのサイドプロジェクトとして進めてきました。
現時点ではTOEIC ®教材に対しての移行が終わり、実際にmikanQTを利用した初の機能として初回模試という機能をリリースすることもできました。
初回模試は、TOEIC を目標にするユーザに向けた、実力判定のための機能となっています。
TOEIC ®のContents QuestionTypeをmikanQTに移行できた一方で、まだまだやるべきことは残っています。
TOEIC ®以外のContents QuestionTypeへの対応Attributeを直接返しているAPI の廃止
EAVの廃止
巨大なJSON を含む場合の対処
ここ数ヶ月は別のプロジェクトが進行中のため、mikanQTの対応はしばらく先になりそうです。
この取り組みはバックエンドもクライアントも幸せになれるものなので、ぜひ時間を取って移行を進めていきたいと考えています。
おわりに
様々な教材を掲載しているmikanならではの課題について書きました。
完全なコードを出さずに説明している部分もあって読みにくかったかと思いますが、少しでもバックエンドチームの取り組みが伝わっていたら嬉しいです。
現在、mikanのバックエンドチームは2名ということで、バックエンドエンジニアを募集中です。
歴史的経緯にリスペクトを持ちつつ、より良い方向へmikanを改善していけるような仲間を探しています。
EdTech、英語学習、Go言語などのキーワードにピンと来たら、ぜひ以下の求人に応募していただけたらと思います。
herp.careers
いきなり応募というのもハードルが高いかと思いますので、カジュアル面談等もお待ちしております。その場合はDMをいただければと思います。
https://twitter.com/kagagaga_ga