はじめに
皆さん、こんにちは!mikanでAndroid エンジニアをしているgumioです。
twitter.com
今回は僕がmikanに入社する前から、今までにメイン業務とは別でしてきたことを紹介していきたいと思います!
個人振り返りみたいなものですが、誰かの参考になれば幸いです。
MTG 改善・集中day1つめにすぐ思い浮かぶのはMTG 改善と集中dayじゃないでしょうか!
僕が入社した当時のmikanは1時間のMTG が細切れで設定されていて、作業に集中できるような状態ではなかったです。
きっかけは単純で1on1の時に、「フルタイムになったのに副業の時より開発時間が減ってるように感じる!」という相談をしました。
なぜ、開発時間が減ったように感じたか?
MTG の曜日がバラバラかつ、1日の中でも細切れになっている
1時間もかからないMTG だけど、多めに取ってしまっているが故に、早めに終わったときに上の細切れを誘発している
これに対して、提案したのは以下のようになっています。
月・金にMTG を寄せてしまう
上記の曜日以外でも必要なMTG を設定する時は連続的になるように調整
1時間以上のMTG は合宿とし、極力1時間未満で済むようにする
mikanのいい所はこういった施策がすぐに試せる環境、だめだったらそれをやめればいいという小回りの効くところだと思います。
当日すぐに定例などのMTG は全体で断捨離、統合、短縮などがされ、月・金に寄せられるようになりました。
その翌日から朝会があるのですが、全体周知で1時間以上のMTG は合宿とします。というアナウンスがされるようになりました。
実施した効果は絶大で生産性が向上したとの声がたくさんあり、今でも継続されてます。
メリット
この取り組み職種問わずに集中して作業する時間が確保されること、MTG -> 作業 -> MTG と言った、スイッチングコストがかからないことで組織全体の生産性を向上させることができます。
デメリット
ないです!ハッピーハッピー!
振り返ってみて
今はまだ1日の枠に収まりきってますが、人が増えると共に開催されるMTG は増えていきます。そうすると何曜日はMTG dayという風に徐々に汚染されていきます。それを防ぐために極力、共有などの非同期で済むようなMTG はしないように、日頃からドキュメントを貯めていく文化づくりを徹底するともっとよくなるんじゃないかなって思いました。ドキュメント文化は絶賛取り組み中です!
Discord導入
2つめはDiscord導入です!
mikanはほぼフルリモートになっており、当時の社内でのコミュニケーション方法はSlackかZoomの二択でした。
そこにDiscordを導入する意味はあるんか?と思う方もいらっしゃるとは思いますが、zoomのみだと、「今話せますか?」などのMTG するまでもないけど、軽く相談したい時にSlackやり取りが発生してから、部屋を立てて、繋ぐことになるので、少しシームレスなコミュニケーションとは言えない気がしました。
会社に通勤してる時は、隣や対面に同僚がいて、今いいですか?だけでやり取りができるのはオフラインのメリットですよね。それを極力オンラインでも実現したいと思い、Discord導入を行いました。
Discord導入の際にやったことは以下のようになっています。
Discordの運用方針ドキュメント作成
Discordのサーバー準備
1ヶ月の仮運用を全体に周知
仮運用終了後に満足度・継続導入できるかのヒアリ ング
運用方針はこんな感じのものを作成しました。これは前職でも導入されていた手法で僕は好きだったので、少し改良して導入してます。
Discord運用方針ドキュメント一部抜粋
運用方法はざっくりと以下のようになっています。
仮想的な自席を用意
自席roomにマイクだけミュートにして、常時参加にする(スピーカーはON)
話しかけたい場合はその人のroomに訪問することでコミュニケーションが成立
自席を離れる場合はroomを出るだけでよく、周りもそれで分かる
話しかけられたくない、集中したい時は1人しか入ることができない集中部屋に入る
Discordは組織アカウントなどのプランがあるわけではなく、招待リンクさえあれば、誰でも入れます。故にセキュリティ的にあまりよろしくないので、業務関係の画面共有・text投稿は行わない
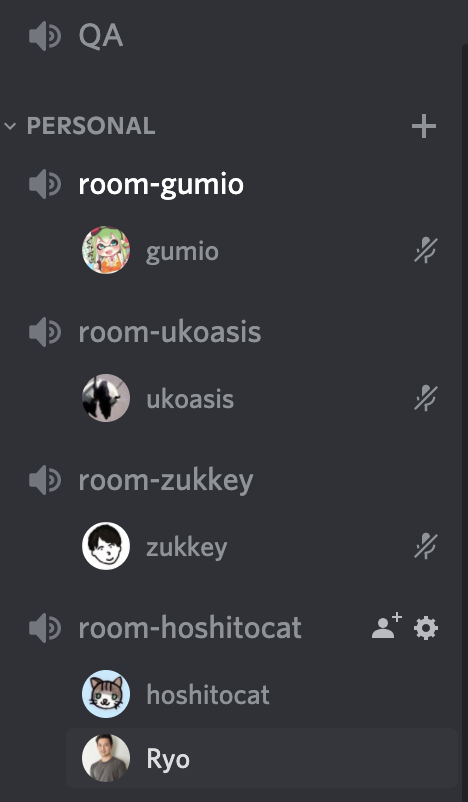
普段の光景はこんな感じです。一部QAなどは音声のみでよいので、Discordで行われていたりします。
いつもの光景
集中したいとき
メリット
Discord導入する前に比べて、気軽なコミュニケーションが取れるようになったという声がたくさん増えました!
余談ですが、Discordは音質がめちゃめちゃいいです。
デメリット
毎朝Discordに入るのが忘れがちになります。
Discordはゲーミングツールなので、ゲームをしない人は日常的に触れる機会はあまりありません。なので、詳しい人が1人いないと推進するのが少し難しいかもしれません。
振り返ってみて
コロナになり、オンラインツールが流行り始めた時に、「各社でDiscordを導入やってみたけど、うまく浸透しなかった。」などの声もたまに見かけますが、なぜmikanでは浸透したのか考えてみた。
意識して、やってみたことは以下です。
ハードルを感じさせないために使い方などをなるべく、画像やgifなどで丁寧に分かりやすく書く
1ヶ月の仮運用からスタートさせ、じわじわと浸透させる
仮運用期間時になるべく便利だ!と思わせるような体験をさせる
使用は強制ではなく、あくまで任意。家庭環境なども考慮しました
浸透するまではSlackリマインダーとか使わずに自分で部屋入りましょう〜!って声掛け
カスタムbot で「Discord入った」って発言されたら、「世界一えらい!!!!」ってめっちゃ褒められるようにした
また、mikanではファーストペンギンに続いてくれるセカンドペンギンが多い組織なのも浸透要因の1つなのではないかと思ってます。
これが実際に効いた!とまでは言わないですが、少なくともDiscord便利じゃん!という体験を仮運用期間にさせてあげるのが1番大きかったのかもしれません。
もちろんうまくいかなかったこともあり、週1の固定時間に皆でDiscordに集まって、仕事を休憩して、雑談する「ゆるゆるmikanタイム」というイベントを設けてたのですが、仕事に追われて参加できる、できないの差が激しく、最近辞めることにしました。この辺りはtryしてみたけど、うまくいかなったから、サクッと辞めたという一例ですね。どうすればうまくいくかを次の施策に活かしてみたいと思います!
mikan LT
3つめは社内LTの実施です!
こちらも前職でやっていた文化が好きだったので、mikanに導入してみました!
導入しようと思ったきっかけは、コミュニケーション活性化のためです。
mikanには社内Notionに1人1人の詳細な自己紹介ページがあるのですが、そこで語られるパーソナルな部分には限りがあると思っていて、それ以上の深い部分は見えてこないと思います。
そこをmikanLTで埋め合わせるために、フリーテーマでその人のパーソナルな部分を好きに語ってもらうことで、社内全体のコミュニケーション活性を図ろうとしたのがきっかけです。
こちらの導入の流れはDiscordとほぼ同様ですが、以下のようになっています。
mikanLTの目的などが書かれたドキュメント作成
毎週金曜日にある、社内全体の定例でやりたい旨を伝える
月1で実施
参加は副業の方問わず、任意参加
目的、尺や配分、テーマについては以下ドキュメントより
補足: 登壇者は毎回挙手か、依頼制で2人選出しています。
mikanLTドキュメント一部抜粋
メリット
オンラインで職種問わずに顔合わせる機会が増えたこと。mikanLTは任意だけど、参加率が非常にいいです。毎回楽しみにしているというありがたい声も頂きました。
デメリット
Qの終わり頃とか月末に近いときに登壇者に選ばれていると追い込まれてると感じてしまう。無理をさせてしまう(ここは口頭カバーで、資料は時間かけずに簡単なペライチだけでもいいという旨はしっかり伝えてある)。
主催者が1人だと最初の導入までの負担がでかい。
振り返ってみて
デメリットにあげているが、自分でこういうのを開催したい!ってなった際にルール決めとか、実施までの負担が意外とでかいことを予測できなかったので、協力者を1人求めればよかったなって思いました。
最初は総合尺を40分とかにしてたのですが、全然時間が足りなくて、結局1時間でいい感じに収まったのですが、1回・2回を通じてブラッシュアップしていけたのはよかったかなと思ってます。
mikan LTをしてる様子
オンボーディング改善プチ協力
4つめはオンボーディング改善プチ協力です!
皆さん、新しいメンバーが来た際にしっかりと迎える準備はできていますか..??
はい、オンボーディングってやつです。
オンボーディングが整ってる、整ってないでは新しく来た人の初動スピード、活躍できるまでの時間に差が生まれると思っています。
充実したオンボーディングを提供することで、その人が会社で活躍できるまでの時間が、グッと縮まるのであれば、リソース割いてでも充実したオンボーディングを作った方がよいと思いませんか??
そもそものきっかけは、Podcast やnote などでもしつこく言っていますが、僕が入社した時のmikanは今のオンボーディングと比較すると整っていなかった状態でした。必要ツールの招待や定例などは都度自分から拾いに行くスタイルでした。
なので、オンボーディングが、、、あばばばばばばbryという感じで機会があるごとに言ってました。(ここですぐにオンボーディング改善したろ!!!ってならなかったのは反省ですね)
そういえば、なんでプチ協力かというと僕はきっかけに過ぎず、実際にアクションを起こしてくれたのはmikanの取締役の溝さんで、僕はきっかけづくりとレビュー対応をしたくらいです。
そこで溝さんが次の入社の人に同じ思いをさせまい!と立ち上がったわけですね。
実際にはオンボーディングの叩きを作ってくださって、僕はそれにこういうのあったら、よかったな〜という視点でレビューをしたという感じです。
僕の屍を乗り越えて、オンボーディング資料が完成したというわけですね。(めでたしめでたし)
新たに作成されたオンボーディング資料について、6, 7人目の正社員のUKさん, まきさんがPodcast で赤裸々に語ってくれているので、よかったらご視聴くださいませ。
anchor.fm
メリット
一度時間かけて汎用的に作成すれば、それ以降は部分アップデートだったり、これからずっと使えるものになります。
新しく来た人が早く活躍できます!
デメリット
ないです!すぐやりましょう!
振り返ってみて
途中でも述べてるのですが、オンボーディングあばばってなった時に僕から、こんなオンボーディングだったら、めっちゃよかったという提案をして作ればよかったなとは思いました。
今ではmikanのオンボーディングは汎用的で、副業の方にも同じように使えます。最近僕はAndroid の副業の方にオンボーディングをしたんですよね。
そしたら、「今から自分は入社するんじゃないかと錯覚しました」と言われました。
まあびっくり。僕の過去の屍も喜んでいます。
人には常に丁寧に寄り添いましょうという学びですね!!!
おわりに
いかがだったでしょうか?エンジニアだからといって、コード周り、チーム内改善のみに留まらずに会社自体を良くしようと動いてみました!
上記で紹介したものは一部のみとなっていますが、インパク トが大きめなものをチョイスして紹介してみました。(今それってあなたの感想ですよね?とか思いました...?)
前職のような大きい企業だと、先人達が整えてきてくださった上で働けるので、あまりこういった改善箇所を見つけるのは難しかったり、そもそも企業の文化によっては行動起こすのが難しいとかはあるかもですね。
スタートアップとかだと整っていなくて荒地なとこは多々ありますが、そこを一人一人が良くしていこうという意識を持てるのと、こういう文化づくりをしたい!というチャレンジがたくさんできるのはいいことだなって思います。
こういうチャレンジは駄目だったら、すぐ辞めればよくて、よかったらもっとよくするためにブラッシュアップしていけばいいので、それもスタートアップならではの動きやすさですね。
今回、少しでも他の企業の方の参考になれば、いいなと思い書いてみました!引き続きmikanで組織がもっとよくなるための行動をおこしてみようと思います!
最後になりますが、mikanでは現在職種問わずに積極採用中です!!!!!!
ぜひ、このような環境で働いてみたいと少しでも思った方、英語好き、教育を変えていきたい方は一緒に働きましょう!!!
採用ページが充実しておりますので、ご覧くださいませ。
mikan.link